Five questions for a PM tool review in 2026
A short rubric to separate tools that look good from tools that drive real impact. Vendor-agnostic on purpose — including against us.
If you lead product, someone on your team has probably asked you, quietly, in the last two weeks: are we still on the right PM tool?
It is a fair question. A category does not go from stable to uncertain without that conversation happening in every company in it. The news of the last month has moved the question from the back of the list to the top.
What follows is a short rubric. Five questions. Honest enough that you can use them on any PM tool on your shortlist, including the one you already pay for. Including us.
We think these five questions matter more than any feature grid right now. The grid will still be useful. But the grid answers a question from 2021. These five answer the question from 2026.
Before the questions, a framing worth holding.
Two postures
A software tool can take one of two postures toward the team that pays for it.
Invested in you. Every release sharpens the product you already bought. The roadmap is tuned to what your stack does well. The upgrades compound the decision you made. The vendor's ambition and your outcome are aligned because the vendor's ambition is to be a better version of the thing you chose.
Needing your investment. Every release is an attempt to become something the tool was not originally. The roadmap is tuned to what the vendor is trying to become. Your fees are capital for that journey. You might still get a good tool in the end. You might not. Either way, you are in a different relationship than the one the pricing page implies.
Most product leaders can tell the difference when they look carefully at two years of release notes. The rhythm of a tool invested in you reads like we heard you. The rhythm of a tool needing your investment reads like we have a new direction.
Neither posture is dishonorable. The second has produced some of the great pivots in software history. But the second is also how teams end up paying a premium to subsidize a reinvention that may or may not arrive. Knowing which posture your tool has taken is the precondition for any serious evaluation.
The grid will still be useful. But the grid answers a question from 2021. These five questions answer the question from 2026.
With that frame, the rubric.
Question 1 — Can we trace any recommendation back to customer signal?
This is the most important question in the rubric. It is also the question the most vendors answer badly.
A product operating system worth paying for should be able to show you, for any recommendation it makes, the exact signals that produced the recommendation. Which calls. Which tickets. Which deals. Which segments. Which conversations. Not a summary of the signal. The chain.
If the trail goes dark — if the vendor can tell you why a recommendation was made but cannot show you what it was made from — you are building your roadmap on a foundation you cannot inspect. This is the quiet risk in AI-enabled PM tools right now. The tool that is wrong in visible ways is manageable. The tool that is right most of the time in ways you cannot audit is dangerous.
Good answer: one click from initiative back to source. Who said it, when, in what context, how it connects to the outcome. The chain is one link, not a research project.
Red flag: manual links, screenshots stitched together by the PM, or a version of "trust me." If the trail requires the PM to rebuild it from memory, the system is not the system; the PM's head is.
A concrete way to bring this into the meeting: ask the vendor to take any recommendation the tool made this quarter and click through to the evidence. Count clicks. Watch what happens when you ask to share the chain with engineering in a single link. The answer to that small request tells you whether the system was built around traceability or around presentation.
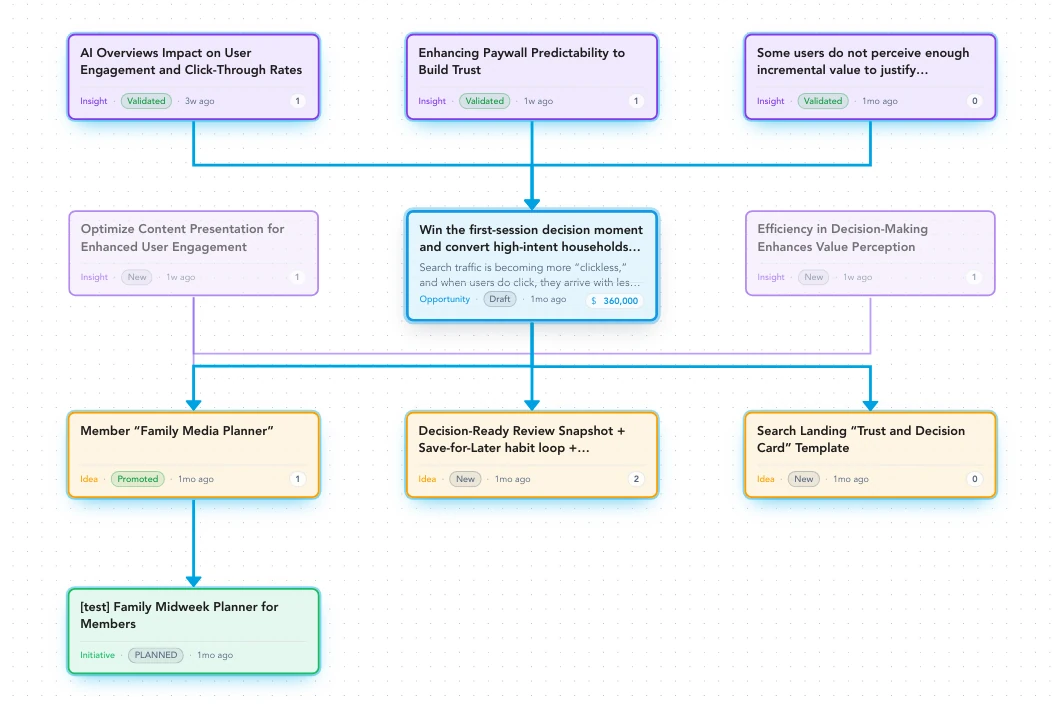
What that should look like in practice:

The image above is illustrative. The chain is real for the teams running Zentrik now: a CSM call gets parsed into a Signal node, the Signal aggregates with seven similar mentions across three accounts into an Insight, the Insight rolls up into an Opportunity weighted by $1.1M of impacted ARR, and the Opportunity informs an Initiative that the Platform PM owns and that has a measurable outcome attached. Every node points back to the source. None of it requires the PM to rebuild the chain by hand.
That is what Q1 looks like when the answer is yes.
Question 2 — Does the tool reflect how our team actually makes decisions?
Most PM tools assume your team works the way the tool's first ten customers worked. Some teams do. Most teams do not.
The question underneath this one is whether the tool can model your operating model — your decision rights, your cross-functional rhythms, the way your specific company's planning meeting actually proceeds — without forcing you to flatten it into the tool's preferred shape.
Good answer: the tool supports your operating model. Decision rights, role permissions, and cross-functional workflows are configurable, not forced. The system bends to your team.
Red flag: the tool forces a process that does not match how you work. The PM ends up "translating" between what the team actually does and what the tool wants to record. That translation is invisible labor; it is also the work the tool was supposed to remove.
A concrete way to ask: walk the vendor through one specific decision your team made last quarter — who weighed in, who decided, what the trade-off was — and ask them to show you, in the tool, where that decision would have lived end-to-end. If the answer requires three workarounds and a custom field, the tool was built for someone else's company.
Question 3 — Can we connect strategy to impact without rebuilding everything?
Roadmaps that are disconnected from outcomes are slides, not systems. Roadmaps that require a six-month migration to "become a system" are also slides — they just have a roadmap to becoming a system.
The question underneath: does the tool let your existing strategy artifacts, roadmap items, and outcomes connect together as your team learns, or does it want you to rebuild your taxonomy from scratch in its preferred shape before the value shows up?
Good answer: strategy, roadmap, and work items link to outcomes, and the links can evolve as your understanding evolves. You can add structure without throwing out what you already know.
Red flag: the roadmap is a presentation surface with no outcome layer underneath. Or the tool wants you to redo your taxonomy as a precondition for getting started. Either way, the tool's value is downstream of work the tool refuses to help with.
The honest version of the AI-era PM tool category is that switching costs are dropping. A modern system of action can read your old tool. The teams that move first benefit; the teams that wait pay the retrofit tax. Make sure the tool you are evaluating can ingest your existing PM data and rebuild the connective tissue automatically — not as a paid services engagement.
Question 4 — Will this AI layer understand our product and our business?
Every PM tool has shipped an AI feature in the last eighteen months. The differences between them are mostly invisible from the marketing page.
The question underneath: when the AI generates a summary, a draft, a recommendation, or a brief, does it understand your specific product, your specific customers, your specific commercial constraints — or is it producing the average answer to a generic question?
Good answer: the AI is grounded in your context. It respects permissions, it knows which accounts matter, it explains its reasoning, and it can tell you when it is unsure. The output reads like it was written by someone who has been at the company for a year.
Red flag: generic summaries that could have been generated for any team. Hallucinations dressed up as confidence. Black-box answers with no path back to the underlying data. The AI is impressive for thirty seconds and then becomes the thing the team turns off.
A concrete way to ask: bring three real signals from your team — a Gong call, a Zendesk ticket, a Confluence page — into the demo. Ask the AI to draft an opportunity brief from them. Read the brief carefully. If you find one sentence the AI made up, you have your answer.
Question 5 — What happens in month six when implementation gets real?
The person on your pitch call is almost never the person you talk to in month six. That is normal. What matters is whether there is a sustainable team on the other side, and whether the company's structure will let that team do its job.
Good answer: clear plan for the first ninety days, real implementation support, and a product that keeps improving without surprise pricing changes. The CS team is named, scoped, and tenured.
Red flag: vague onboarding, a handoff to "customer success" with no specific person attached, or a vendor that has restructured three times in the last two years. Whether the product is good has stopped being the only question. Whether the team behind it can hold together long enough to serve you well has become part of the evaluation.
A concrete way to ask: how many CS people on your team in the ratio to accounts my size, who is the CS lead on my account, and how long has the average CS person on your team been at the company? The answers tell you more about your future with a vendor than any feature promise.
The questions do not tell you which tool to buy. They tell you what you are actually buying.
How to use the rubric
Print it. Bring it into the next vendor call. Ask the questions in that order. Ask them of your incumbent first, because the incumbent's answers calibrate what realistic looks like across the rest of your shortlist.

A team we work with did this rubric last quarter without naming it. They ended up staying with their incumbent for twelve more months — but they renegotiated the contract on much more honest terms, because they stopped buying the narrative and started buying the architecture underneath. Another team we work with did the same rubric and decided to switch. Both were the right call.
The wrong call is not asking the questions.
A disclosure, because this rubric applies to us too
We built Zentrik as a product operating system with evidence at its core. AI-native architecture from the start, not a graft on an older product. A discovery graph where every recommendation traces back to specific customer signals in one click. A roadmap tuned to what our existing customers already ask for, not a pivot to what the industry thinks is next.
If you run these five questions on us, we believe we answer them honestly and well. We also believe we fall short in specific places that a one-hour conversation with one of our pilot teams would surface, which is why we run those conversations openly rather than performing a demo on demo data.
The rubric is yours regardless. Use it on whoever is on your shortlist, including the tool you already pay for. The questions belong to your team, not to any vendor.
If you are interested in what the next four weeks of essays from us look like — ingestion, auditability, MCP, and recommendations, one Tuesday at a time, building toward a launch on June 16 — the next post drops Tuesday May 12. The rubric here is the framing those four essays will earn against, including against us.
Jab Co-founder, Zentrik